- 查詢Heap Size 參考網址
- java -XX:+PrintFlagsFinal -version | grep HeapSize
- 設定head size給程序
- java -Xmx5120m package.class
- 打包jar
- # cd 指定目錄
- 準備 manifest.mf 內容
- Main-Class: 含有程式進入點(main方法)的Main Class名稱
- # jar -cvfm XXXXX.jar manifest.mf A.class B.class
2017/8/31
Hadoop 練習筆記 - spark-submit (5)
- 建立可執行之Jar檔供spark執行
- Fat-jar
- Fat-jar也就叫做UberJar,是一种可执行的Jar包(Executable Jar)。
- FatJar和普通的jar不同在于它包含了依赖的jar包
- Maven 打包方式 , 各有其目的
- 打開eclipse建立一個maven專案
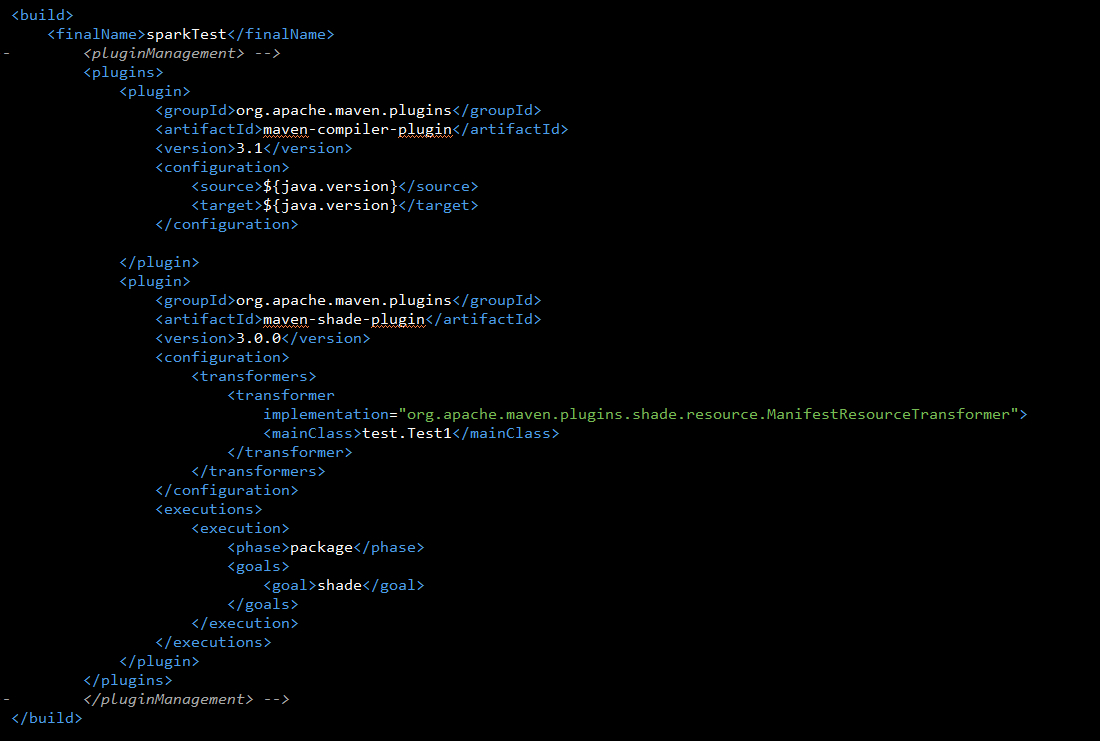
- pom.xml 內容
- spark scope=provied , 代表在打包成jar檔時不含 , 因OS環境已有相關套件
- 利用maven-shade-plugin 打包成可執行的 fat-jar檔案
- 令其名為sparkTest

- test.Test1.java
- 簡單輸出 hello!!字串

- 執行 mvn package進行打包 , 在target目錄下將產生兩個jar檔
- sparkTest.jar (包含所有相依class)
- original-sparkTest.jar (僅包含自己的class)
- 將sparkTest.jar丟入/home/spark/shareFolder/這個共用目錄
- 切換spark使用者
- su - spark
- 啟動spark standalone模式(前幾篇已經設定完畢)
- start-all.sh
- 檢查web UI介面 , spark 是否已經啟動
- 將jar檔丟給spark執行結果

2017/8/23
Linux NFS Mount 筆記
- Server端
- 參考網址 參考網址 參考網址
- 建立掛載目錄
- mkdir /share/server
- 編輯可掛載目錄
- nano /etc/exports
- /share/server/ [ClientIP.0/24](rw,no_root_squash,no_all_squash,sync)
- 權限:(rw,no_root_squash,no_all_squash,sync)
- 開啟服務
- service nfslock restart
- service rpcbind restart
- service nfs restart
- 問題處理 參考網址
- Client端
- 建立目錄
- mkdir /share/client
- 顯示server可mount的目錄
- showmount -e [ServerIP]
- Mount目錄
- mount -t nfs master:/share/server/ /share/client
- 檢驗結果
- Client端 開機自動掛載 參考網址 參考網址
- 設定檔案
- nano /etc/fstab
- master:/share/server /share/client nfs defaults 0 0
- 無須重開機 , 測試
- mount -a
- 解除mount
- umount /share/client
- 強制 -l
Hadoop 練習筆記 - Spark - Standalone mode (4)
- 建議完成第一篇環境
- Spark幾種部署方式 參考網址
- Local Mode
- YARN Mode
- Standalone Mode
- HA Mode
- Mesos Mode
- Standalone Mode
- 完成local mode安裝
- 將local mode完成之spark目錄scp至所有slave主機上
- 參考之前的文章 ,建立無密碼SSH連線至所有slave主機上
- 設定Master主機上 , conf/salves 檔案 , 加入以下
- slave1
slave2 - 執行sbin/start-all.sh 啟動Standalone Mode
- 進入管理介面驗證 , master:8080

- 啟動一個spark程序交由standalone
- spark-shell --master spark://master:7077
- 在管理介面port 8080 將多一條程序

- 讀取檔案 textFile 将本地文件或 HDFS 文件轉换成 RDD
- 進入 spark-shell --master spark://master:7077
- 本地文件
- 需要各節點都有同一份文件
- 依照測試的結果 , master會先在本地端檢查是否有該檔案 , 再呼叫work node再各自的本地端找尋檔案
- 可使用mount 去 shard folder , 依照本篇作法 , 自行mount目錄
- 測試結果
- local 路徑應用 : "file:///home/spark/shareFolder/test

- HDFS文件
- 先將自製文件上傳到hdfs
- su - hadoop
- hadoop fs -mkdir /spark
- hadoop fs -chown -R spark /spark
- hadoop fs -put /test /spark/test
- su - spark
- spark-shell --master spark://master:7077
- var aaa = sc.textFile("hdfs://master:9000/spark/test")

2017/8/16
Hadoop 練習筆記 - Spark - local mode(3)
參考網址


- 建議完成第一篇環境
- Spark幾種部署方式 參考網址
- Local Mode
- YARN Mode
- Standalone Mode
- HA Mode
- Mesos Mode
- Local Mode
- Master主機 , slave主機都建立使用者 spark
- useradd spark
- passwd spark
- 切換使用者
- su spark
- 依照Master主機環境下載 Scala , Spark
- 解tar以後放入 /home/spark
- /home/spark/scala-2.12.3
- /home/spark/spark-2.2.0-bin-hadoop2.7
- 設定環境變數
- nano /home/spark/.bash_profile
- source /home/spark/.bash_profile
- 啟動Spark , 驗證是否安裝完畢
- 透過不同參數決定用何種模式啟動spark 參考網址
- spark-shell
- 另外可透過web UI port 4040 檢驗

2017/8/15
Hadoop 練習筆記 - HBase(2)
- 完成前篇Hadoop環境後
- Master主機 , Slave主機新增使用者 hbase , 並完成SSH無密碼連線 , 可參考前篇
- Master主機
- 切換使用者來完成以下操作
- su hbase
- 下載最新hbase-1.2.6-bin.tar.gz 解壓縮放在 /home/hbase/下
- 設定環境 hbase-env.sh
- nano /home/hbase/hbase-1.2.6/conf/hbase-env.sh
- export JAVA_HOME=/usr/java/jdk1.8.0_141/
- remark 兩行 , 因jdk 8 已不適用 , 會有error 參考網址
- #export HBASE_MASTER_OPTS="$HBASE_MASTER_OPTS -XX:PermSize=128m -XX:MaxPermSize$........
- #export HBASE_REGIONSERVER_OPTS="$HBASE_REGIONSERVER_OPTS -XX:PermSize=128m -XX$
- 修改設定檔hbase-site.xml
- nano /home/hbase/hbase-1.2.6/conf/hbase-site.xml
- <configuration><property><name>hbase.cluster.distributed</name><value>true</value></property><property><name>hbase.rootdir</name><value>hdfs://master:9000/hbase</value></property><property><name>hbase.zookeeper.quorum</name><value>master</value></property></configuration>
- 修改設定檔regionservers
- nano /home/hbase/hbase-1.2.6/conf/regionservers
- slave1
slave2 - 做到此可將 Hbase資料夾複製到所有slave上
- scp -r hbase-1.2.6 slave1:~/
- scp -r hbase-1.2.6 slave2:~/
- 設置環境變數
- export HBASE_HOME=/home/hbase/hbase-1.2.6export HADOOP_CLASSPATH=$HBASE_HOME/lib/*
export PATH=$HBASE_HOME/bin:$PATH - source ~/.bash_profile
- 啟動 hadoop
- start-all.sh
- 建立hbase用目錄 參考網址
- hadoop fs -mkdir /hbase
- hadoop fs -chown -R hbase /hbase
- 啟動 Hbase
- /home/hbase/hbase-1.2.6/bin/start-hbase.sh
- 開啟firefox進入web UI檢驗結果 參考網址
- In HBase newer than 0.98.x, the HTTP ports used by the HBase Web UI changed from 60010 for the Master and 60030 for each RegionServer to 16010 for the Master and 16030 for the RegionServer.

2017/8/14
SSH無密碼登入一些問題處理筆記
- 切換需要之使用者
- su test
- 建立公鑰私鑰
- ssh-keygen
- 一路enter
- 傳輸公鑰至遠端主機
- ssh-copy-id [遠端帳號]@[遠端IP]
- 測試SSH 是否無須密碼
- ssh [遠端帳號]@[遠端IP]
- ssh [遠端帳號]@[遠端IP] whoami
- 仍需密碼之處理
- 遠端ssh server 設定 參考網址
- nano /etc/ssh/sshd_config , 確認是否開啟
- StrictModes yes
#當使用者的 host key 改變之後,Server 就不接受連線,可以抵擋部分的木馬程式! - RSAAuthentication yes
# 是否使用純的 RSA 認證!?僅針對 version 1 - PubkeyAuthentication yes
# 是否允許 Public Key ?當然允許啦!僅針對 version 2 - AuthorizedKeysFile .ssh/authorized_keys
# 上面這個在設定若要使用不需要密碼登入的帳號時,那麼那個帳號的存放檔案所在檔名! 這個設定值很重要喔!檔名給他記一下! - 遠端目錄權限 (放寬反而無效) 參考網址
- /home => 754 (待確認)
- /home/test => 754
- /home/test/.ssh => 700
- /home/test/.ssh => 600
2017/8/11
Hadoop 練習筆記 - HDFS(multi mode) (1)
參考網址
參考網址










參考網址
- 目標 : 建立 Hadoop 實現分散式環境
- 準備 : CentOS 7 * 3
- 1 master , 2 slave
- 在master主機 /etc/hosts 設定三台domain
- 192.168.100.100 master
- 192.168.100.101 slave1
- 192.168.100.102 slave2
- 建立hadoop帳號密碼 , 在master主機建立ssh-key鑰 參考網址 , 參考網址
- useradd hadoop
- passwd hadoop
- su hadoop
- ssh-keygen
- ssh-copy-id hadoop@192.168.100.101/102
- 測試無密碼 ssh連線
- 將hadoop 設為最高權限 (可執行所有指令)
- root -> visudo
- 加入此行 " hadoop ALL=(ALL) ALL "
- 安裝Oracle jdk, 移除open jdk 參考網址
- 至官方下載最新jdk
- su -
- 安裝rpm yum install jdk-8u51-linux-x64.rpm
- 變更預設jdk
- alternatives --config java
- 如果未出現選項先update
- update-alternatives --install /usr/bin/java java /usr/java/jdk1.7.0_79/bin/java 300
- 移除openjdk
- rpm -qa | grep openjdk
- yum remove -y [套件名稱]
- 建立JAVA_HOME
- nano /etc/profile
- export JAVA_HOME=/usr/java/jdk1.8.0_141
- source /etc/profile
- env | grep java
- 至官網下載hadoop 安裝檔 2.8.1放置在 /home/hadoop下
- 配置XML
- core-site.xml (是核心配置,為 hadoop 指定基本配置信息)
- hdfs-site.xml (配置hdfs参数,比如備份數量)
- mapred-site.xml (配置map-reduce属性)
- 已改由yarn取代
- yarn-site.xml (配置yarn属性)
- Master主機
- HDFS設定
- nano /home/hadoop/hadoop-2.8.1/etc/hadoop/hdfs-site.xml

- 核心的主機交換資料位址設定
- nano /home/hadoop/hadoop-2.8.1/etc/hadoop/core-site.xml

- 使用 yarn 管理 MR
- nano /home/hadoop/hadoop-2.8.1/etc/hadoop/mapred-site.xml

- yarn-site 的資源管理員設定
- nano /home/hadoop/hadoop-2.8.1/etc/hadoop/yarn-site.xml

- 環境變數
- nano /home/hadoop/hadoop-2.8.1/etc/hadoop/hadoop-env.sh
- export JAVA_HOME=/usr/java/latest
- nano /home/hadoop/hadoop-2.8.1/etc/hadoop/yarn-env.sh
- export JAVA_HOME=/usr/java/latest
- Slave主機
- yarn-site 設定
- nano /home/hadoop/hadoop-2.8.1/etc/hadoop/yarn-site.xml

- mapred 由 yarn 管理
- nano /home/hadoop/hadoop-2.8.1/etc/hadoop/mapred-site.xml

- HDFS 設定
- nano /home/hadoop/hadoop-2.8.1/etc/hadoop/hdfs-site.xml

- 核心主機
- nano /home/hadoop/hadoop-2.8.1/etc/hadoop/core-site.xml

- 添加環境變數
- source .bash_profile

- 格式化 hdfs 檔案系統
- master
- rm -rf /home/hadoop/namenode
- mkdir /home/hadoop/namenode
- 格式化namenode資料夾
- hdfs namenode -format
- slave
- rm -rf /home/hadoop/datanode
- mkdir /home/hadoop/datanode
- 設定Node
- master
- nano /home/hadoop/hadoop-2.8.1/etc/hadoop/slaves
- 加入 slave1 slave2
- 啟動hadoop
- cd /home/hadoop/hadoop-2.8.1/sbin/start-all.sh
- 驗證
- master觀看 HDFS 驗證
- hdfs dfs -mkdir /home
- hdfs dfs -ls /
- master使用 dfsadmin 觀看報表
- hdfs dfsadmin -report
- master使用jps查看進程
- 應有 NameNode , SecondaryNameNode , Jps , ResourceManager
- slave使用jps查看進程
- 應有NodeManager , DataNode , Jps
- master查看瀏覽器管理介面
- http://localhost:50070
- 啟動後查看管理介面
- http://localhost:50070/ – web UI of the NameNode daemon
- http://localhost:50030/ – web UI of the JobTracker daemon
- http://localhost:50060/ – web UI of the TaskTracker daemon
訂閱:
文章 (Atom)